




















Limitless Potential of Data Ops and AI
Introduction

Traditional DataOps challenges

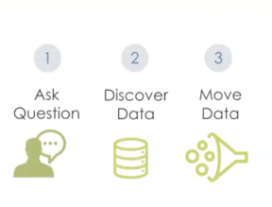
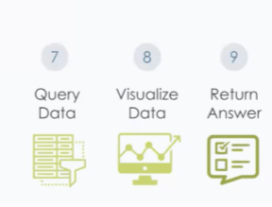
Inspironlabs, AI-Led DataOps Framework
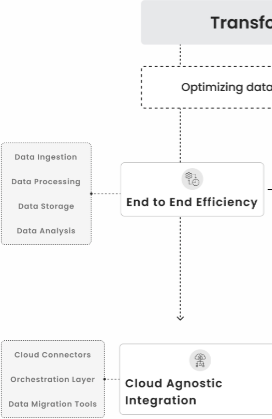
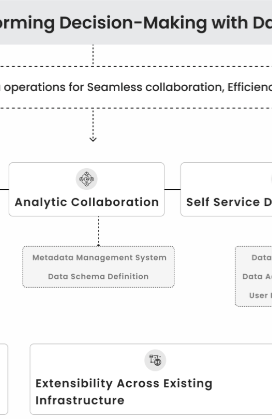
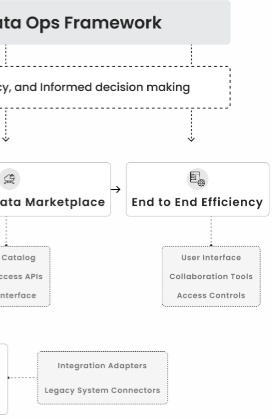
Our Services enabling you to take informed decisions at early stages
We efficiently manage testing environments with our AI enabled tools, enabling create, duplicate, and isolate sandbox environments for testing and validation. This ensure production environment stability during development and testing.
What makes us more reliable in DataOPs
Limitless Potential of Data Ops & AI with InspironLabs!
Author’s Profile

Introduction
Fraud is one of the biggest challenges faced by modern financial institutions, e-commerce platforms, and digital payment providers. Every year, billions of dollars are lost to fraudulent transactions. With the rise of real-time digital payments, fraudsters are becoming more sophisticated, making traditional fraud detection methods—like rule-based batch processing—insufficient.
What organizations need today is the ability to analyze massive transaction streams in real time and detect suspicious patterns instantly. This is where Apache Flink and Apache Spark come into play. Both are open-source, distributed data processing frameworks widely adopted for big data fraud analytics. But when it comes to real-time fraud detection, they serve different purposes and complement each other beautifully.

In this blog, we’ll explore:
- The differences between Flink and Spark jobs.
- How their execution models impact fraud detection using machine learning.
- Practical scenarios where each framework fits best.
- How combining them builds a complete fraud detection system for businesses.
Apache Spark: The Powerhouse for Historical and Batch Analysis
Apache Spark is one of the most widely used big data platforms for fraud detection. It was designed for batch processing, and later extended with Structured Streaming to support fraud detection in near real-time use cases.

Execution Model
- Spark streaming operates on a micro-batch model. Instead of processing each event as it arrives, Spark groups data into small batches (e.g., every 1–2 seconds) and processes them together.
- This makes Spark very effective for big data fraud analytics, but not for ultra-low-latency requirements.
Strengths for Fraud Detection
- Historical Analysis: Spark can process terabytes or petabytes of historical transaction data to identify long-term fraud patterns.
- Model Training: Using Spark’s MLlib or integrating with external ML frameworks, financial institutions can train sophisticated fraud detection machine learning models.
- Scalability: Spark can easily scale horizontally to process data from millions of users across years of activity.
Limitations
- Because of its micro-batch nature, Spark’s latency is typically in seconds. In fraud prevention in banking and finance, a delay of even a few seconds may allow a fraudulent transaction to go through.
Spark is excellent for offline fraud analytics and model training, but less suitable for real-time fraud detection.
Apache Flink: Built for Real-Time Fraud Detection
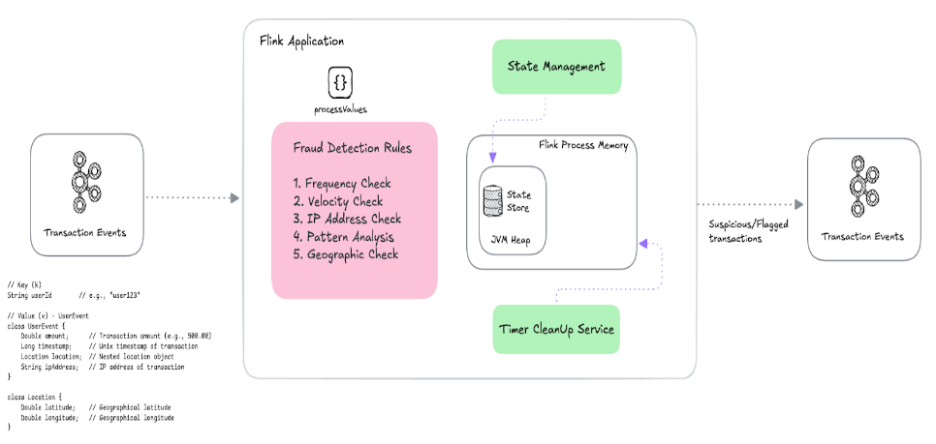
Apache Flink was designed from the ground up for real-time data processing for fraud detection. Unlike Spark, Flink does not rely on batching—it processes each event immediately as it arrives, making it ideal for digital payment fraud prevention.
Execution Model
- Flink uses a true streaming model, meaning it processes events one at a time.
- It maintains stateful computations in memory, enabling it to track patterns across multiple events with millisecond latency.
Strengths for Fraud Detection
- Low Latency: Flink’s millisecond-level processing ensures suspicious transactions can be flagged or blocked instantly.
- Complex Event Processing (CEP): Flink can detect patterns across multiple events, such as:
a. Three failed login attempts followed by a high-value transfer.
b. Transactions from the same card occurring in different countries within minutes.
c. A series of low-value transfers designed to stay below detection thresholds.
- State Management: Flink can track user sessions and behavior across events, which is crucial for identifying anomalies in financial fraud detection systems.
- Fault Tolerance: With checkpoints and savepoints, Flink guarantees data consistency even in case of system failures.
Limitations
- Flink has a steeper learning curve and a smaller machine learning ecosystem compared to Spark.
- It often requires integration with external ML libraries for advanced fraud models.
Flink is the go-to solution for real-time fraud detection and prevention.
Combining Spark and Flink for Fraud Detection
Instead of choosing one over the other, the most effective fraud detection solutions for enterprises leverage both Spark and Flink:
1. Model Training with Spark
- Spark processes historical data to train machine learning fraud detection models.
- These models can classify transactions as fraudulent or legitimate based on historical patterns.
2. Real-Time Detection with Flink
- The trained models are deployed into Flink jobs.
- Flink scores each incoming transaction in real time and applies CEP rules to detect suspicious activity.
- If fraud is detected, Flink can instantly raise an alert or block the transaction.
Example Workflow
- A bank streams transactions into Kafka.
- Flink consumes the stream, applies fraud detection logic (rules + ML scoring), and outputs alerts in milliseconds.
- Spark periodically processes historical data to retrain fraud detection models, improving accuracy over time.
This hybrid approach ensures:
- Accuracy → from Spark’s large-scale data analysis.
- Speed → from Flink’s low-latency event processing.
Executive View: Why It Matters
From a business perspective, the choice between Flink and Spark isn’t about one replacing the other. It’s about leveraging their strengths:
- Spark: Helps businesses stay ahead of fraud trends by learning from the past.
- Flink: Protects businesses in the moment, preventing fraudulent activity before damage occurs.
A fraud detection system for digital payments and banking built on both technologies can:
- Reduce fraud losses by stopping suspicious transactions in real time.
- Improve customer trust with faster, safer digital payments.
- Scale to handle millions of transactions per second without compromising accuracy.
How InspironLabs Delivers Real-World Impact
Harnessing the power of Apache Spark and Flink is not just about understanding their capabilities—it’s about applying them strategically to solve real business challenges. At InspironLabs, we specialize in turning these technologies into practical, high-impact fraud detection solutions for clients across fintech, e-commerce, and digital payment ecosystems.
- For Banking & Financial Institutions → We build real-time fraud monitoring solutions that can instantly flag suspicious transactions, reducing financial losses and protecting customer trust.
- For E-commerce Platforms → We integrate e-commerce fraud detection systems that track abnormal shopping behaviors, card misuse, and account takeovers with millisecond latency.
- For Digital Payment Providers → We help deploy scalable, low-latency digital payment fraud prevention architectures capable of handling millions of concurrent transactions without downtime.
By combining Spark’s large-scale model training with Flink’s real-time scoring and CEP rules, InspironLabs enables clients to stay ahead of fraudsters—continuously learning from historical data while reacting instantly to new threats.
Conclusion: Building Future-Ready Fraud Detection Systems
Fraud is evolving, but so are the technologies to fight it. By leveraging the power of Apache Spark and Flink together, businesses can achieve both long-term fraud intelligence and real-time fraud detection.
At InspironLabs, we help organizations implement advanced fraud prevention systems—tailored to their business scale, security requirements, and compliance needs. Whether you’re looking to modernize your fraud detection infrastructure or build one from scratch, our expertise ensures faster, safer, and more reliable digital transactions.
Learn more about how we can support your fraud detection initiatives: inspironlabs.com Or connect with us directly: Contact Us



